In the Previous blogs we have seen about virtual memory related concepts.
http://sqlandmorewithkruti.blogspot.in/2016/01/memory-fundamentals-for-sql-server.html
We came across concepts like Address Window Extension, Physical Address Extension.
We also saw the various CPU related architectural concepts and briefly touch based SQLOS.
In this blog we shall see how SQL server memory is divided.
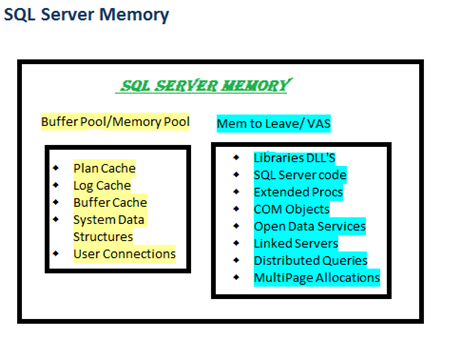
When SQL server starts memory is first reserved for the MEM To Leave area also known as Virtual Address Space Reservation area. This is not user configurable. Windows Memory Management allows user process to reserve a contiguous block of address space without actually consuming committed pages. This is called VAS reservation or MEM to Leave. Components of the Mem To Leave area are mentioned above. All allocations for a contiguous memory block larger than 8KB come from the MemToLeave region. it's possible that allocations smaller than 8KB could end up coming from the MemToLeave region.
The default size of Mem To Leave region is 256MB but can be changed using the -g parameter during SQL server startup.
Next comes the BUFFER Pool
Calculation of BufferPool Region
We have the maximum server memory option for any SQL server instance. This option decides the amount of memory that will be allocated for the Buffer Pool region. Bpool consists of 32 separate memory regions organized into 8KB pages.
In 32-Bit Systems
Once the MemToLeave region is occupied the remaining Virtual Address Space is checked. The remainder of the VAS is calculated and reserved for SQL server. If this value is less than Max Server Configuration then that becomes the size of the Buffer Pool.
The calculation of the Buffer Pool size however differs if the AWE is enabled and /PAE switch is used. Here the physcial memory on the server or the max server memory configuration setting, whichever is smaller becomes the size of the Buffer Pool.
In 64-Bit Systems
There is no need to use AWE to allocate memory above 3GB for SQL Server since the user mode VAS is 8TB there is always ample VAS to utilize all of the physical memory available on the server.
For 64 bit servers, the maximum size of the BPool is the size of physical memory or the max server memory configuration, whichever is smaller. For example, a 64 bit server with 16GB RAM, and a default max server memory configuration, the maximum size of the Bpool would be 16GB.
SQL server memory logical level tree

As described in the previous blog it’s a logical unit in which SQL server access memory.

Memory Clerks
Memory clerks access memory nodes to allocate memory to different objects. Information on different types of memory clerks is listed using the below query. Till SQL server version 2008 you will be able to see the segregation of the single pages allocated and multiple pages allocated for particular objects.
select distinct type from sys.dm_os_memory_clerks where
type like 'mem%' order by type.
Memory Caches
SQL Server uses three types of caching mechanism: object store, cache store, and user store.
Object Store :
Object stores are used to cache homogeneous types of stateless data. Each entry within this store can be used by only one client at a time. SQLOS does not control the lifetime of the entries in the object store type of cache. Hence it does not implement Least Recently Used (LRU) Algorithm for costing the entries and maintaining their lifetime. One example for use of an object store is the SNI, which uses the object store for pooling network buffers. No state, no cost , all buffers of the same size.
User Store:
User stores are used for objects that has its own storage user's mechanism. How the objects are stored depends on the underlying development framework. SQLOS controls the lifetime of entries and maintains a cost based on LRU algorithm. One example of User Store objects is metadata cache.
Cache Store:
For cache store the lifetime is fully controlled by SQLOS's caching framework. The storage mechanism is SQL OS managed. SQLOS does this with what is called the hashing technique wherein the entry for each object is stored in one or multiple tables. This supports for faster look-ups. SQLOS controls the lifetime of entries and maintains a cost based on LRU algorithm. Object Plans (CACHESTORE_OBJCP), SQL Plans (CACHESTORE_SQLCP), Bound Trees (CACHESTORE_PHDR), Extended Stored Procedures (CACHESTORE_XPROC) all fall within this cache store.
I recommend you go through the below blogs to study further.
http://blogs.msdn.com/b/slavao/archive/2005/03/18/398651.aspx
http://blogs.msdn.com/b/slavao/archive/2005/08/30/458036.aspx
http://blogs.msdn.com/b/slavao/archive/2005/02/19/376714.aspx
https://msdn.microsoft.com/en-us/library/cc293624.aspx
Thus SQL server memory gets divided into various stores. On the whole MemToLeave and BufferPool is what comprises the SQL server memory. In the next blog we shall see how SQL server responds to memory pressure. How the memory caches are accounted for based on LRU & hashing algorithms.