
SQL server has the capability to store text-based data in the form of char, varchar, nchar, nvarchar, text, ntext, image, xml, or varbinary(max). When querying the data stored in such columns the “LIKE” clause would be highly used for pattern matching.
7) Thesaurus
Thesaurus comprises of synonyms or word expansions for any given word. Each language has its own set of defined synonyms. This is an XML file stored in file system. This broadens our search criteria to find similar words at querying time.


2) Query is passed to the SQL server engine comprising of SQL Server Query Processor and Full-Text Engine along with various other components
3) The Full-Text searches are sent to Full-Text Engine during both the stage Compilation and Execution. SQL Server Query Processor is responsible for parsing, binding, optimization and execution.The Full-Text Engine receives the Full-Text part of the queries from the query processor. It works in conjunction with the SQL server query processor.
4) In order to full the requests a Full-Text engine calls for the Indexer. The indexer is responsible for evaluating the StopList and populating Full-Text Indexes which form a part of the database from SQL server 2008 onwards. Prior to this they were stored separately on file systems. StopList will also contain stopwords which are ignored during query evaluation.
5) Thesaurus is used during Full-Text query compilation and execution. Its external to the SQL server database. This file is also used by the Filer Daemon Launcher Service which is again external to the SQLservr.Exe
6) Filter Daemon Manager is responsible for monitoring the Filer Daemon Launcher Service or Host Service.Its external to the SQL Server Engine.Inside SQL server engine the user tables are evaluated during full-text index population or crawl process by the indexer. This data is also used by the Filter Daemon Manager process which passes this information to the Host Service.
7) The Filter Daemon Host is responsible for accessing, filtering, and word breaking data from tables, as well as for word breaking and stemming the query input: It comprises of
a) The protocol handler which is responsible for pulling SQL server data from memory and passing the database data to the filter.
Consider the below table

However consider the scenario where I wish to check if Jeremy is one of the characters in the books based on the synopsis given. My query would look something like this
A special token-based index built and maintained by the Full Text Engine for SQL server. It is used to track occurrences of words or word-forms in columns containing unstructured text. Full-Text index structures are different from normal B-tree index structures. It’s an inverted, stacked, compressed index structure based on individual tokens from the text being indexed. Only one Full-Text index can be created per table. It does require a unique key to be set for each row for the given table. It helps to keep this key as small as possible. This could be a primary key. This structure is elaborated in the following link
https://technet.microsoft.com/en-us/library/ms142505(v=sql.105).aspx
2) Full-Text Catalogs
It’s a logical container for Full-Text indexes. A database can have one or more full-text catalogs. The indexes are aggregated as a collection in terms of catalog purely for administration and maintenance purpose. It is used to set common property values for all the indexes it stores.
CREATE TABLE [dbo].[Books](
[id] [int] IDENTITY(1,1) NOT NULL,
[Author] [varchar](20) NULL,
[Title] [varchar](100) NULL,
[Published_yr] [date] NOT NULL,
[Synopsis] [nvarchar](max) NULL,
CONSTRAINT [pk_id] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO

SQL script for the table
dbo.Books.sql
It would be easier if we were filtering the rows based on authors something like this
dbo.Books.sql
It would be easier if we were filtering the rows based on authors something like this
SELECT * FROM BOOKS WHERE Author LIKE 'Nicholas%'
SELECT * FROM BOOKS WHERE Synopsis LIKE '%Jeremy%'
It will work fine doing a table scans for the pattern match. However consider if this was a library management system consisting of millions of records. In such a scenario performing a table scan over a table is not a wise option. For such situations SQL server provides a functionality called full-text search. SQL Server's full-text search engine gives you fast queries and advanced pattern matching in an enterprise environment. It works against text data in full-text indexes by operating on words and phrases based on rules of a particular language such as English.
To understand its architecture and how it works we need to familiar ourselves with its terminologies.
https://technet.microsoft.com/en-us/library/ms142581(v=sql.105).aspx
1) Full-Text Indexes
https://technet.microsoft.com/en-us/library/ms142581(v=sql.105).aspx
Full-Text Terminologies
A special token-based index built and maintained by the Full Text Engine for SQL server. It is used to track occurrences of words or word-forms in columns containing unstructured text. Full-Text index structures are different from normal B-tree index structures. It’s an inverted, stacked, compressed index structure based on individual tokens from the text being indexed. Only one Full-Text index can be created per table. It does require a unique key to be set for each row for the given table. It helps to keep this key as small as possible. This could be a primary key. This structure is elaborated in the following link
https://technet.microsoft.com/en-us/library/ms142505(v=sql.105).aspx
2) Full-Text Catalogs
It’s a logical container for Full-Text indexes. A database can have one or more full-text catalogs. The indexes are aggregated as a collection in terms of catalog purely for administration and maintenance purpose. It is used to set common property values for all the indexes it stores.
3) Word Stemmers
For any language like English we have certain words which are considered as base or root words. From these new-words or its conjugates can be formed. Consider the word “Eat” from this we can derive words like “eating, will eat, shall eat, ate, etc” these are its derived forms. Such words are called stemmers. Identifying the word stemmers comes in handy for pattern searching while using full-text indexes.
4) Word Breakers
4) Word Breakers
Any characters which delimit sentences or phrases for the language are called word breakers (Spaces Excluded). They are particular for each supported language in SQL server. Once identified further action can be taken in building the FTS index or processing the query.
5) StopWords and StopList
5) StopWords and StopList
Every language has certain words like conjunctions, pro-nouns which provide no meaningful benefit when used in search criteria’s. For example words like “the, are, and, to,etc” are commonly discarded for full-text indexes. These words are called stopwords. By excluding these words the Full-Text indexes become more efficient. The indexes however do take into account the position of such words when encountered. As the name suggests StopList is a list of Stop words. SQL server lets you create & customize your own StopLists.
https://technet.microsoft.com/en-us/library/ms142551(v=sql.105).aspx
6) Population / Crawl Process
Unlike standard SQL Server indexes that are automatically maintained during data modifications full-text indexes aren’t repopulated. Creating and maintaining a full-text index involves populating the index by using a process called a population (also known as a crawl). There are 3 modes of population
A) Full Population - As the name suggests builds full-text indexes for all the rows of the table. Similar to that of a standard index rebuild operation. The default behavior of SQL server is to populate a new full-text index fully as soon as it is created.
B) Change Tracking-Based Population /Update Population This uses change tracking functionality of SQL server. SQL server maintains a table which tracks modifications made to the index after its initial full population. Based on CHANGE_TRACKING property of the index whether set to AUTO or MANUAL the indexes are populated.Default behavior is Automatic Change_Tracking.
C) Incremental Timestamp-Based Population - This requires that the indexed table has a column of timestamp data type. If such a column does not exists SQL server will treat it as a full population operation. If the column exists SQL Server will update the modified rows based on the value of the time-stamped column.
https://technet.microsoft.com/en-us/library/ms142575(v=sql.105).aspxC) Incremental Timestamp-Based Population - This requires that the indexed table has a column of timestamp data type. If such a column does not exists SQL server will treat it as a full population operation. If the column exists SQL Server will update the modified rows based on the value of the time-stamped column.
7) Thesaurus
Thesaurus comprises of synonyms or word expansions for any given word. Each language has its own set of defined synonyms. This is an XML file stored in file system. This broadens our search criteria to find similar words at querying time.
Thesaurus matching occurs only for CONTAINS and CONTAINSTABLE queries that specify the FORMSOF THESAURUS clause and for FREETEXT and FREETEXTABLE queries. The default location for the thesaurus files is as follows
<SQL_Server_data_files_path>\<VersionSpecificInstance>\MSSQL\FTDATA\
C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\FTData
Beginning in SQL Server 2008, full-text search supports more than 50 diverse languages, such as English, Spanish, Chinese, Japanese, Arabic, Bengali, and Hindi. Once can check the list of supported full-text languages using the following query
<SQL_Server_data_files_path>\<VersionSpecificInstance>\MSSQL\FTDATA\
C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\FTData
Beginning in SQL Server 2008, full-text search supports more than 50 diverse languages, such as English, Spanish, Chinese, Japanese, Arabic, Bengali, and Hindi. Once can check the list of supported full-text languages using the following query
SELECT * FROM sys.fulltext_languages
There are a list of system tables corresponding to fulltext which you can view for each of the above described components
Full-Text Index Architecture
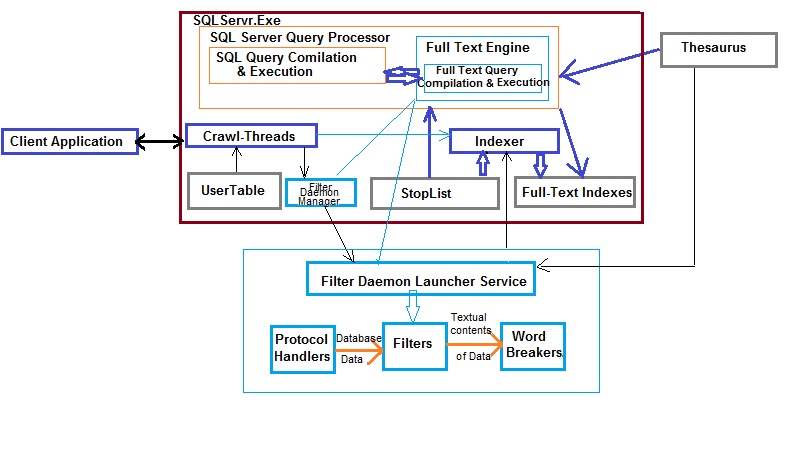
1) Client application submits a query containing Full-Text search contents
2) Query is passed to the SQL server engine comprising of SQL Server Query Processor and Full-Text Engine along with various other components
3) The Full-Text searches are sent to Full-Text Engine during both the stage Compilation and Execution. SQL Server Query Processor is responsible for parsing, binding, optimization and execution.The Full-Text Engine receives the Full-Text part of the queries from the query processor. It works in conjunction with the SQL server query processor.
4) In order to full the requests a Full-Text engine calls for the Indexer. The indexer is responsible for evaluating the StopList and populating Full-Text Indexes which form a part of the database from SQL server 2008 onwards. Prior to this they were stored separately on file systems. StopList will also contain stopwords which are ignored during query evaluation.
5) Thesaurus is used during Full-Text query compilation and execution. Its external to the SQL server database. This file is also used by the Filer Daemon Launcher Service which is again external to the SQLservr.Exe
6) Filter Daemon Manager is responsible for monitoring the Filer Daemon Launcher Service or Host Service.Its external to the SQL Server Engine.Inside SQL server engine the user tables are evaluated during full-text index population or crawl process by the indexer. This data is also used by the Filter Daemon Manager process which passes this information to the Host Service.
7) The Filter Daemon Host is responsible for accessing, filtering, and word breaking data from tables, as well as for word breaking and stemming the query input: It comprises of
b) The filter extracts chunks of data from the input provided by protocol handler. This is dependent on the document type. The embedded formatting is removed by the filter retaining only the textual contents and their position information. This result-set is then passed to the work-breakers.
c)The word-breakers delimit the result-set. These word-breakers are also passed to the indexer by the Filter Daemon Launcher Service. Just like the stoplist the word-breaker are ignored
c)The word-breakers delimit the result-set. These word-breakers are also passed to the indexer by the Filter Daemon Launcher Service. Just like the stoplist the word-breaker are ignored
8) During indexing process the indexer uses all of the above result-set namely
- Tokenized daata from full-text crawl threads
- Delimited result-set from the Filter Daemon Host Service
- Stop-list words that are to be excluded
It then creates index-able words to inverted index fragments. All these fragments are then merged to form the full-text indexes for the tables
9) During the querying process the Full-Text Engine uses the full-text indexes generated by the indexer. The word-breakers and thesaurus are first referenced to generate all forms of query predicate. The query processor then looks-up for all these forms in the full-text indexes. The Full-Text Engine is also responsible for the optimization process much like a standard query optimization process to retrieve the data.
10) The SQL query execution results and Full-Text query execution results are combined and the final result-set is sent across the client.
9) During the querying process the Full-Text Engine uses the full-text indexes generated by the indexer. The word-breakers and thesaurus are first referenced to generate all forms of query predicate. The query processor then looks-up for all these forms in the full-text indexes. The Full-Text Engine is also responsible for the optimization process much like a standard query optimization process to retrieve the data.
10) The SQL query execution results and Full-Text query execution results are combined and the final result-set is sent across the client.
In the next blog we shall see how to create Full-Text Catalogs,Indexes and how to use full-text index queries.
It will be nice if you can share real life examples
ReplyDeleteHi Tanweer,The examples given here were self created and hypothetical. Haven't come across any where I could implement the same. But if I do or come across where its implemented I'll surely note it down and have it shared. Thanks for you feedback.
Delete